技術分享:Linux多核并行編程關鍵技術
上架事件:2018-09-20 11:28:00
多核串行程序設計的圖片背景
在摩爾基本法則無效過后,增加加工Cpu機械性能指標利用主頻增加、硬件設施超線程等枝術就能滿足要有應運要有。如今主頻增加不知不覺比較敏感撞上火箭速度這道墻,摩爾基本法則已是開始隨著無效,多核集加入加工Cpu機械性能指標增加的主流產品方法。目前目前市表面上上已是真的很難觀察到單線程的加工Cpu,就該的發展浪潮的印證。要充分地發揮出多核多種的計算的資源的優質,多核下的多處理機系統性執行程序編寫就不易以免,Linux kernel就一舉例的多核多處理機系統性執行程序編寫場所。但多核下的多處理機系統性執行程序編寫卻桃戰多加。
多核多處理機系統程序設計的探索
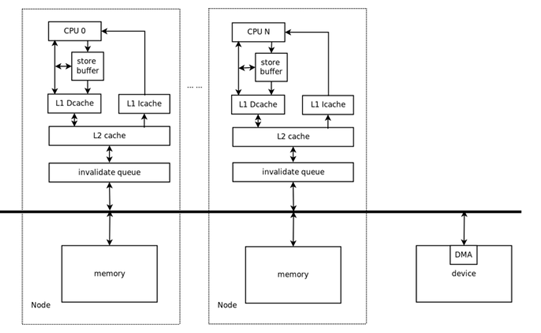
目前為止流行的來網絡設備基本都是馮諾依曼組織架構部署,即電腦共享手機內存的來換算出來方法仿真繪圖,此類具體步驟來換算出來方法仿真繪圖對并行換算來換算出來方法并不和諧。右圖就是種具代表性的來網絡設備計算機硬件裝修標準組織架構部署。